Index of Contents:
Linguistic Watermark Configuration
- The Linguistic Watermark Configuration File
- Structure of a Linguistic Interface
- Configuring the Linguistic Watermark
- Loading a linguistic resource
Linguistic Watermark Configuration:
The Linguistic Watermark component can be embedded in other applications and provide API for loading linguistic resources and accessing their content.
When started, the Linguistic Watermark component scans the working directory looking for available linguistic interfaces. These interfaces come up in the form of jar files whose manifest contains the following entry:
LinguisticInterfaceClass: < classpath of the java class implementing the LinguisticInterface interface >
The Linguistic Watermark component is aware of the existence of available linguistic interfaces and is thus able to invoke their functionalities.
Linguistic Watermark Configuration File
The Linguistic Watermark is configured on the basis of a single configuration file. Here is an example of a compiled configuration file:
We can observe that the file is mainly constituted of three separate sections:
- The Applications section
- The Interfaces section
- The Instances_specification section
The first section represents a sort of cache of the last loaded resources, with a different record for each application which has used the LWatermark. Each application invoking the Watermarj functionalities on the same configuration file, may use a personal id (lie ONTOLING, in the above case), so that the Watermark will keep track of its preference resource
The second section defines and sets those parameters which have a global influence on each specific linguistic interface. For example, the Dict Interface, which is based on a third party library, needs to know where its configuration file (databases.xml) is located. Then every specific configuration is demanded to that file
The third part is dedicated to configuration parameters which are local to a given resource. In the above example, the instance WordNet_2.0 inform the LW that all the JWNL configuration parameters for loading WordNet 2.0 are in the file file_properties.xml. In the same manner, the dan-eng instance informs the Dict Interface about the specific dictionary file which must be loaded (see description of Dict Interface).
Structure of a Linguistic Interface
Since there is no a-priori knowledge about the number of parameters which can characterize a given linguistic interface, how can the whole framework be easily extended?
The answer is in the configuration described above. Every
LinguisticInterface is characterized by some configuration
parameters (usually represented as integer or strings). These parameters can
be described as
InterfaceProperties or
InstanceProperties. The
LinguisticInterfacesFactory is then in charge of assigning values to
those parameters for the loaded resources, taken from the configuration file.
Configuring the Linguistic Watermark
The properties structure of a Linguistic Interface is also exploited to produce, at run-time, graphic user interfaces for configuring its parameters. The chosen settings can then be saved in a new Linguistic Watermark configuration file.
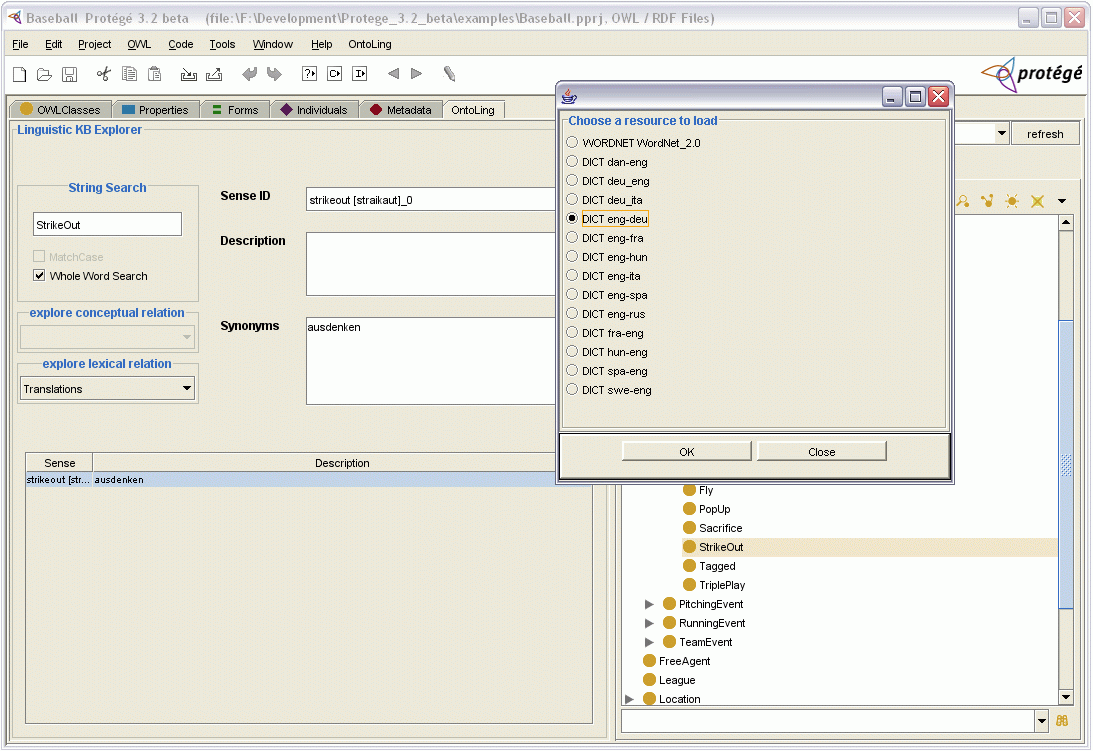
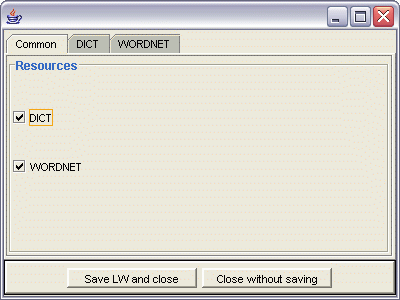
The Linguistic Watermark configuration utility can be invoked through dedicated API to open a window (see figure below), listing the available linguistic interfaces (see notes in the intro):
By clicking on the different tabs, it is possible to access and edit the configuration settings for the various resources. In figure below, the configuration settings for the Dict Interface are showed.
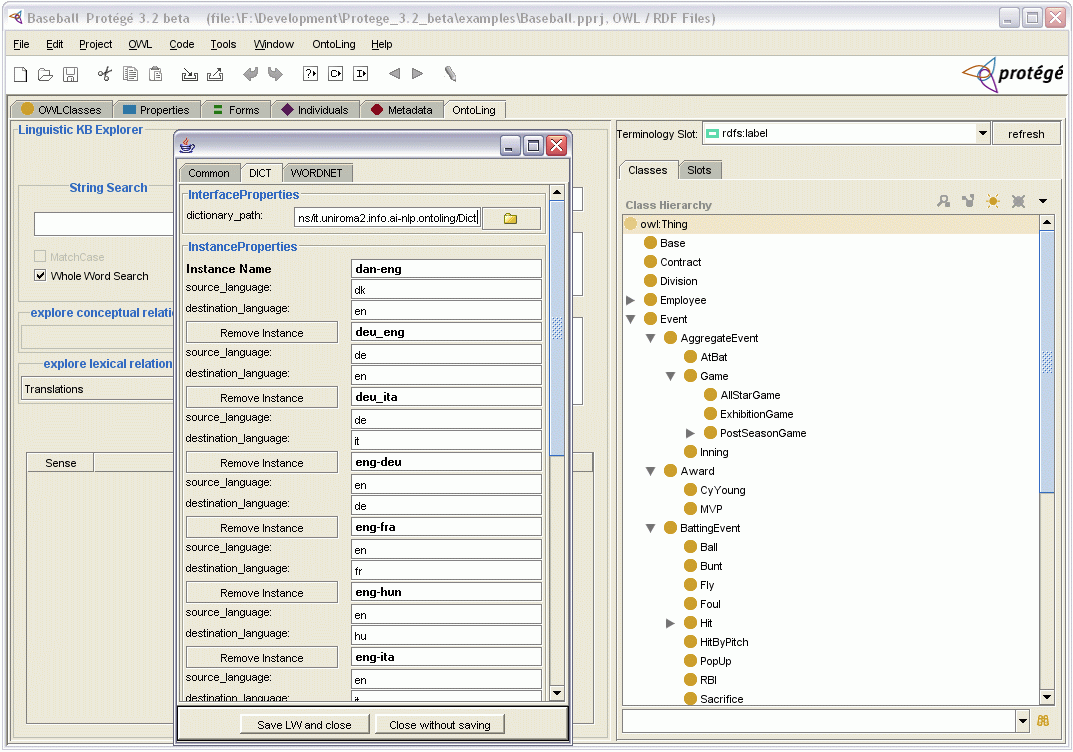
See User Manual of Linguistic Watermark for more details on LW configuration and of specific configuration parameters for the various resources
Loading a Linguistic Resource
The Linguistic Watermark loadiong utility can be invoked through dedicated API to open a window listing all the available linguistic resources (those resources which can be accessed through any of the loaded linguistic interfaces):