

Sheet2RDF Conventions and Heuristics
Sheet2RDF allows for very detailed customization of the projection procedure by means of CODA's rule language PEARL.
However, in the attempt to make the tool as much user-friendly (or naive-user-friendly :-) ) as possible, we have followed a convention-over-configuration approach, for which the datasheet is pre-processed and analysed, looking for known patterns which may have a well established target result, and thus a precompiled projection pattern in PEARL.
We thus embedded a series of heuristics in the system, which cover many recurring patterns from known vocabularies, and added partial support for declaring properties from any kind of vocabulary yet from the datasheet. For anything else...well you gotta learn some PEARL ;-)
So, here's how to import data from a datasheet, and the conventions which may be followed in order to save later PEARL editing:
The datasheet file to be imported is looked for available sheets. In particular:
- There must be (well it's obvious! :-) ) at least one sheet.
- The first (or sole) sheet of the input file must contain the data.
- An optional other sheet (which has to be named "prefix_mapping") may contain prefix-namespace pairs (prefix in 1st column, namespace in 2nd). Both sheets must be populated starting from the first row.
The datasheet (1st sheet of file) should be structured as follow:
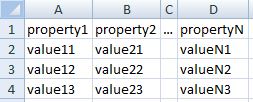
that is, the first row contains the list of headers. The assumption is that roughly each row corresponds to an entity description and that each triple in this description can be built from each column of the datasheet, by considering the identified entity as the subject, the predicate as something inferreable from (or explicitly associated to) the header of the column, and the object as (an RDF node obtained from) the value in the cell at the crossing between the row and the column.
Obviously, it is possible to have even more complex configurations, and a description of an entity could be sparse across different rows, but this is the assumption which Sheet2RDF tries to do in order to automatically fill a PEARL projection document.
So, we have used a lot of "inferred/obtained/processed" etc.. how to get these elements in an automatic way, and how to customize them?
For the subject, there are mainly two possibilities:
- it may be derived from the value stored in the cell under a column
- it may be randomically generated (not seeded by the sheet's content), just one per each row
So, in the first case, the general structure of the excel file will be like this
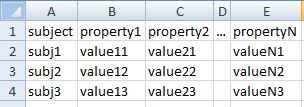
this condition is fired when the header of a column (for simplicity it is the first, but not necessarily) is the the name of an owl:Class (it is checked against the loaded RDFModel). If that is the case, the column is elected to contain the subjects of the RDF triples which will be generated. A deterministic CODA converter will be used to generate an ID based on the cell content, and a triple of the form
<subj> a <specified class>
will be written.
Note that in case multiple column headers have the name of a class, only the last one will be considered the subject column.
The logic underlying the structure of the datasheet will thus produce the following RDF triples:
subj1 property1 value11 ;
property2 value21 ;
propertyN1 valueN1 .
subj2 property1 value12 ;
property2 value22 ;
...
names for headers may follow two conventions:
- a valid qname (e.g. "skos:prefLabel")
- a custom name (e.g. "name").
In the first case, for the qname to be meaningfully used, its prefix should be mappable to a given namespace, by means of one of the following:
- the prefix is known a priori by the system (i.e. skosxl, skos, owl, rdfs, rdf,...)
- the prefix/namespace mapping is present into the input Model
- prefix/namespace is reported into the prefix_mapping sheet
In any of the above cases, the predicate of the generated triple is named generated directly from the qname reported in the header. Not only, in some particular cases (e.g. skosxl:Labels, which are elaborated into at least two triples due to the reification of the label into a URI), the recognized property could fire the automatic generation of more complex triple patterns in the target PEARL document.
In the second case (or if none of the three conditions for valid qnames is satisfied) a placeholder is generated in the target PEARL document and it must be properly grounded in order for the PEARL processor to generate the triples.
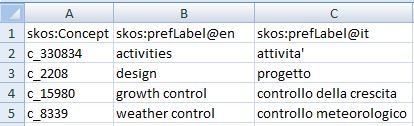
Another convention in the header is relative to untyped literals. If the property mentioned in the header should point to language tagged literals, then it is possible to mention the language in the header name brackets. An example is reported in figure below, where "skos:prefLabel@en" is meant to automatically associate the english language tag to values of the property skos:prefLabel specified in its column values.
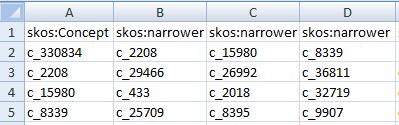
Finally, in Sheet2RDF it is also possible to provide multiple values for the same property. This can be easily accomplished by writing the same property name as the header of adjacent columns, as in the following example where concepts are explicitly mentioned in the datasheet, and a same skos:Concept has more skos:narrower Concepts.
For some practical examples see the tutorial page.