The Sheet2RDF VocBench tool
Sheet2RDF is also available as embedded VocBench 3 tool.
Installation
On the VocBench site, we provided detailed instructions for the installation of VocBench.
Sheet2RDF on VocBench
Once the installation is complete, you can start playing with VocBench. The user interface of Sheet2RDF consists of a tab, which can be opened by clicking on Sheetrdf under Tools navigation bar menu item.
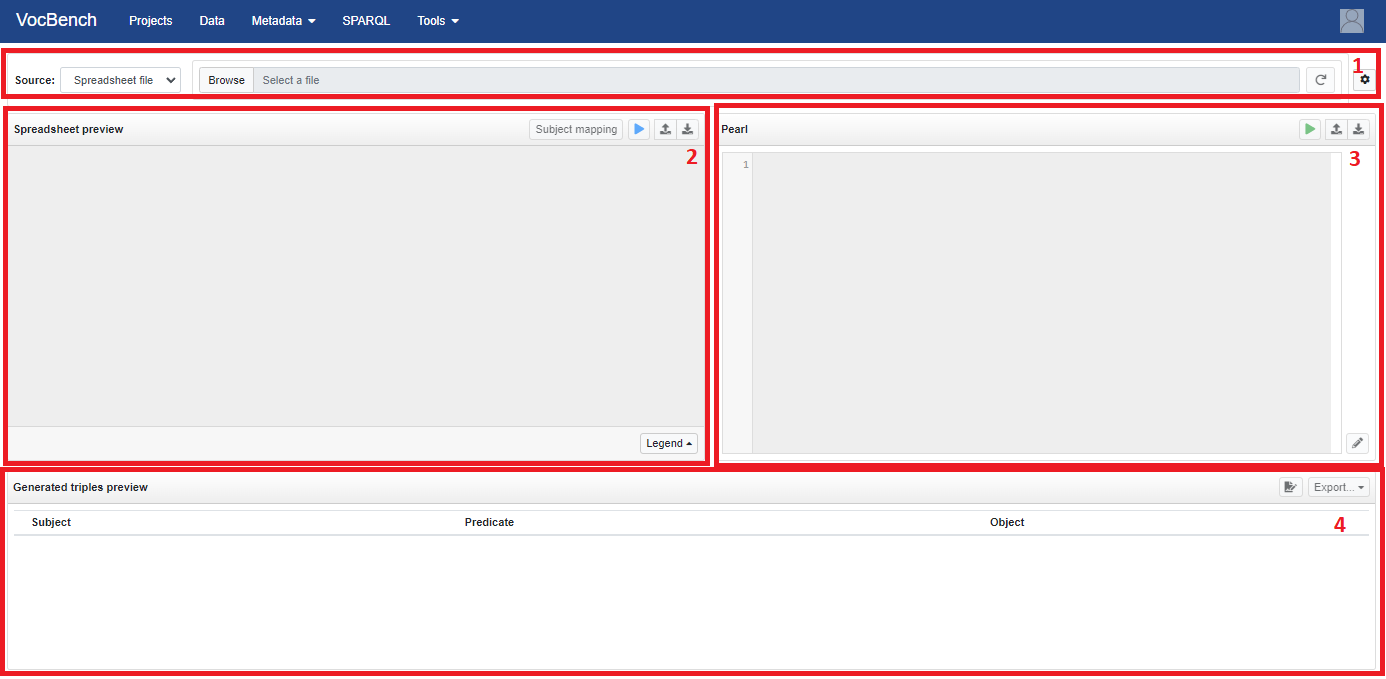
The UI is composed of four panels:
- the upper panel (1) to choose whether the input source is a datasheet or a DB
- the left panel (2) provides a preview of the datasheet content and allows to customize the transformation process;
- the right panel (3) allows to managing the PEARL document;
- the bottom panel (4) shows the rdf triples generated by the system.
Now, let's see how Sheet2RDF works.
Spreadsheet or Database
The first step in using Sheet2RDF in VocBench is deciding whether the input will be a Spreadsheet or a Database. This is achieve by simply selecting Spreadsheet file or Database in the Source menu:
- Spreadsheet:

- Databaase:

Once the user has selected the input source, different informations have to be provided (the source file for the Spreadsheet or the connection parameters for the Database). More information in the next sections.
Multiple Sheets/Tables
Sheet2RDF is able to to support multiple Sheets (from the same Spreadsheet) or Tables (from the same Database).
Each Sheet/Table is represented in the UI as a sub-tab and the user is able to switch between these Sheets/Tables by just clicking on the name of the desired sub-tab.
For example, the following figures show a Spreadsheet having two distinct Sheets (an almost identical UI is shown when multiple tables are selected in a Database):
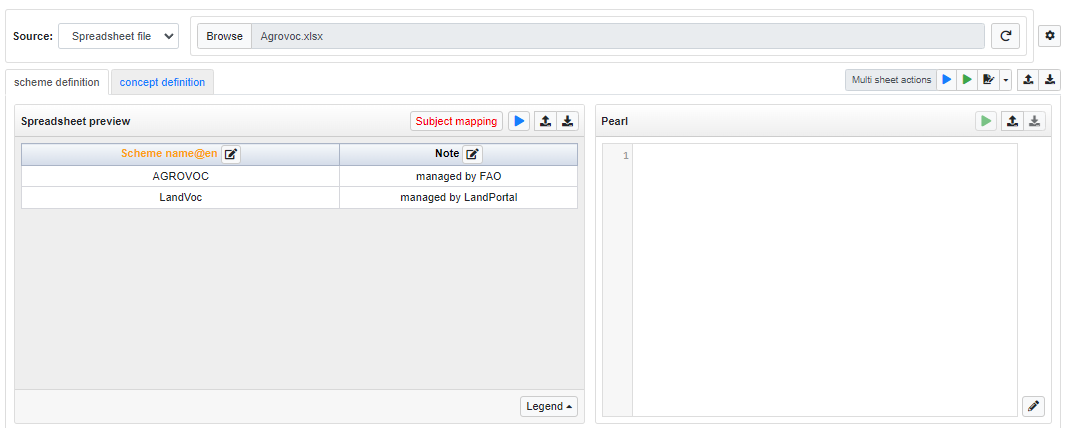
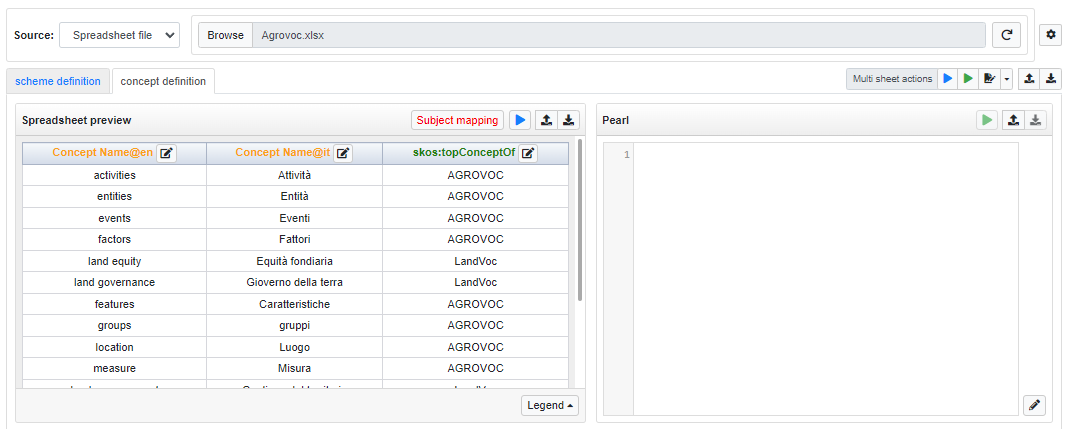
In a Spreadsheet, all its Sheets are automatically loaded, while in Database only the selected Tables are considered.
The spreadsheet management
The input file (the spreadsheet to be processed) can be chosen and loaded through the Browse button. Once the input file is loaded, a preview of the datasheet is shown into the left panel. In the screenshot below, it is shown how is adopted a color code for the column headers status.
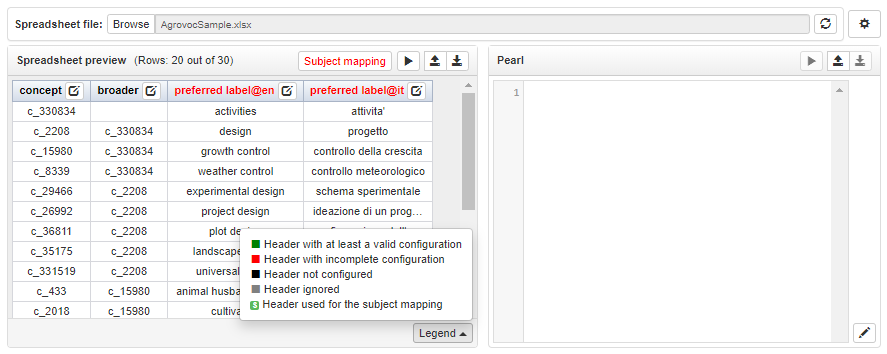
The spreadsheet columns need to be configured in order to guide the triplification process. This configuration will guide the automatic generation of the PEARL code which can be triggered by clicking the "play" button. Note that beside this button, two further buttons are available. These allows to export the current configuration so that it could be imported, edited and reused at a later time.
In order to edit the header configuration, a dedicated dialog can be opened by clicking on the small icon near the column name.
The header editor
In order to better understand the usage of the header editor, it's important to clarify that the PEARL code (which is automatically produced according the configuration of the headers) is the real "brain" of the triplification process. The header editor is just a tool that simplifies the writing of the PEARL code, or even completely relieves the user from the task. In order to completely understand the PEARL language it is recommended to read its documentation, but for the use made of it in Sheet2RDF it is sufficient to know that the PEARL that it is going to be generated is composed essentially by two blocks: nodes and graph. Summarizing briefely:
- The
nodesblock defines a set of RDF nodes using CODA converters which, taking as input UIMA features (in our case they represent the content of the spreadsheet cells), precess and transform their content producing RDF values. - The
graphblock uses the nodes defined in the previous and "projects" them, with a SPARQL-like syntax, in an RDF graph according the subject-predicate-object paradigma
Note: as we will see, whenever a graph application works in "delete" mode, the graph block will be replaced by two blocks: insert and delete .
So, practically, the header editor allows to define a set of nodes and their application in the graph section (named graph applications).
It is possible to completely exclude an header from the process of generation of the PEARL, simply by checking the ignore header checkbox.
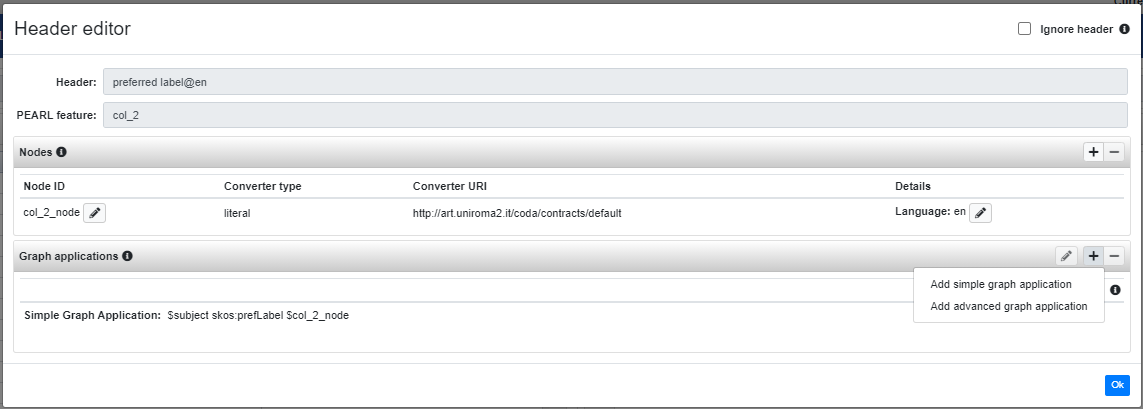
As can be seen in the figure above, the header editor has to immutable fields:
- Header: tells the name of the editing header
- PEARL feature: tells the id with which is referred the UIMA features (related to the cells under the current header) in the PEARL code
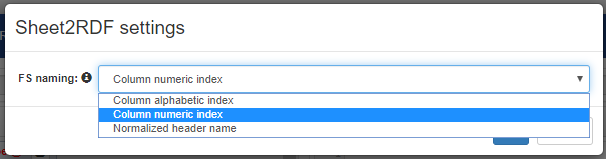
- Column alphabetic index: it names the feature concatenating the prefix
col_with a letter according the alphabetic order:col_A,col_B,col_C,...; - Column numeric index: this is the default choice, it names the feature with the same logic of the alphabetic strategy, but using the column indexes (0-based) instead (e.g.
col_0,col_1,col_2,...); - Normalized header name: normalizes the header name by replacing any non-alphanumeric character with a single
_. To prevent that multiple header with the same name collide on the same feature name, even this strategy adds a prefix following the Column numeric index one. So, for example, the headerpreferred label@en, in third column, would generate the featurecol_2_preferred_label_en.
Let's go back to the description of the header editor. Besides the two fields just described, there are two panels: one for the nodes and one for the graph section.
The nodes panel allows only to delete the nodes or to change minor details (like the language of literal converters, or the configuration of uri converters), it is not possible to create nodes directly from here, so let's focus to the Graph applications panel.
There are two kind of graph application:
- Simple: allows to mapping directly the header with a property, to generate a node compliant with the range of the chosen property and then to define a mapping with a simple subject-predicate-object statement from the column content.
- Advanced: as suggested by the name, it is a more complex mechanism than the simple one. It gives to the user more freedom in order to define even complex graph patterns that go beyond a simple S-P-O triple.
Simple graph application
In most cases, the triplification of the content of a column doesn't require to define a complex graph pattern, the desired output could stick to the simple subject-predicate-object pattern. In this cases the creation of a simple graph application is enough.
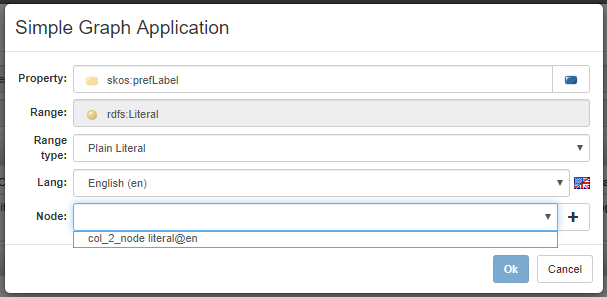
The above form guides the user in the creation of a simple graph application. The primary information is the property to be bound to the column, which have to be looked up on the underlying ontology. Depending on the chosen property, the range field is automatically filled (this is read only, it is just useful to inform the user) as well as the range type combobox which the available value are resource, plain literal and typed literal. The selected value here affects the nature of a further field, indeed in case of resource, a type field optionally allows to assert a type for the column content (it will determine an additional triple like cell_content rdf:type chosen_type), in case of plain literal, a lang field allows to specify the language and finally in case of typed literal a datatype field allows to specify the datatype of the content.
The last field to fill is node. From the dropdown combobox it can be selected one of the nodes already defined in the current header, or click on the + button for creating a new one. Note that in the example shown in the figure, there is already a node defined. This is defined automatically by the system since, according the heuristics, the @en suffix in the preferred label@en header implicity associates a language tagged value (a literal node) to the comlun content.
If the user chooses to create a new node, a form like the following is prompted.
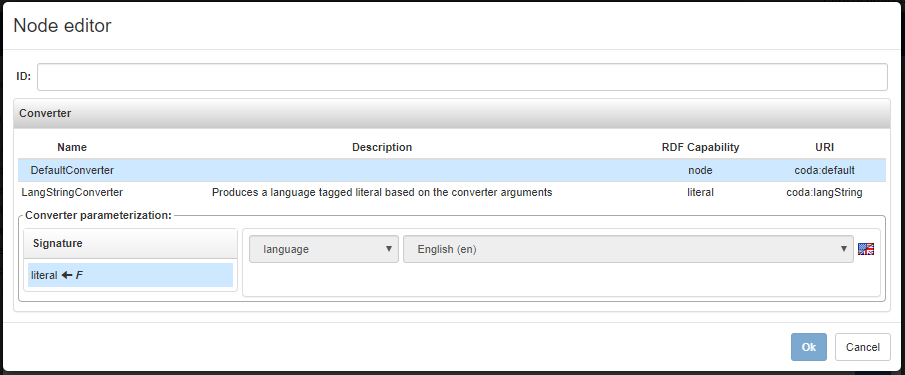
Here the user needs to provide:
- an ID of the node
- a CODA converter with the associated configuration for the generation of the same node. The list of available converters are filtered according the choices made in the previous form. See the tutorial page, for hints on how to choose a suitable converter. As can be seen, in the case taken in example, since the chosen range type was plain literal, there are available only the converters capable to generate a language tagged literal node. Note also that some parameter might be forced as well, like the language forced to english, as chosen previously
The simple graph application determines, in the PEARL nodes section, the serialization of triples like the following in the nodes and graph sections:
nodes = {
...
nodeId node_conversion UIMA_feature/value
...
}
graph = {
...
$subject chosen_predicate $nodeId
...
}
A graph application can also work in "delete" mode, namely instead of adding the subject-predicate-object triple, it will delete the triple. In order to accomplish that is enough to check the Delete option of the graph application as in the following figure.
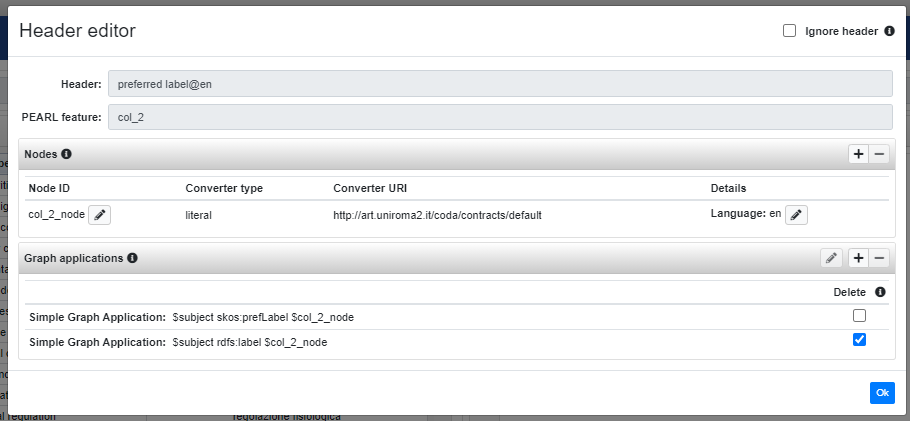
In such case the graph section will be replaced by the blocks insert, for the triples to add, and delete for those to delete. The example shown above will generate the following
nodes = { ... }
insert = {
OPTIONAL { $subject skos:prefLabel $col_2_node . }
}
delete = {
OPTIONAL { $subject rdfs:label $col_2_node . }
}
What if the user wants to define a more complex pattern in the graph section? For example, what if from the content under the preferred label@en column it is wanted to generate a reified label (like in SKOSXL)? The simple graph application doesn't support this intent, so it is necessary to create an advanced graph application.
Advanced graph application
The dialog for creating an advanced graph application consists in two panels: Nodes and Graph. The first basically allows to manage the nodes that are used in the graph pattern. The Graph panel provides a textare for writing the graph pattern. This pattern will be written as it is in the resultant PEARL code.
The following figure shows an advanced graph application that fits the configuration of an header for a SKOSXL lexicalization, indeed it defines two nodes, one for the skosxl:Label IRI and one for the literal form, and then refers to them in the graph pattern.
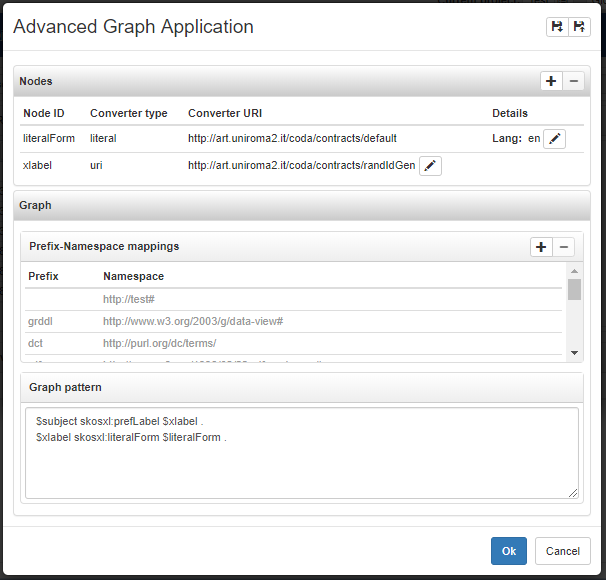
In the graph panel there is also a sub-panel that lists the prefix-namespace mappings defined in the VB project and eventually allows to define further mappings useful in the graph pattern.
The creation of this kind of graph applications could be quite complex, so Sheet2RDF provides the possibility to store and load advanced graph applications in an internal storage in order to reuse them. By default, the storage contains already a factory-provided configuration for the mapping of skosxl:Labels. This storage can be accessed (for loading or storing) by clicking on the "floppy-disk" buttons at the top-right corner of the dialog.
Mapping the subject
Beside the configuration of the columns, in the process of PEARL generation, Sheet2RDF needs to know how to mapping the subject. Clicking on the Subject mapping button, the following dialog pops up.
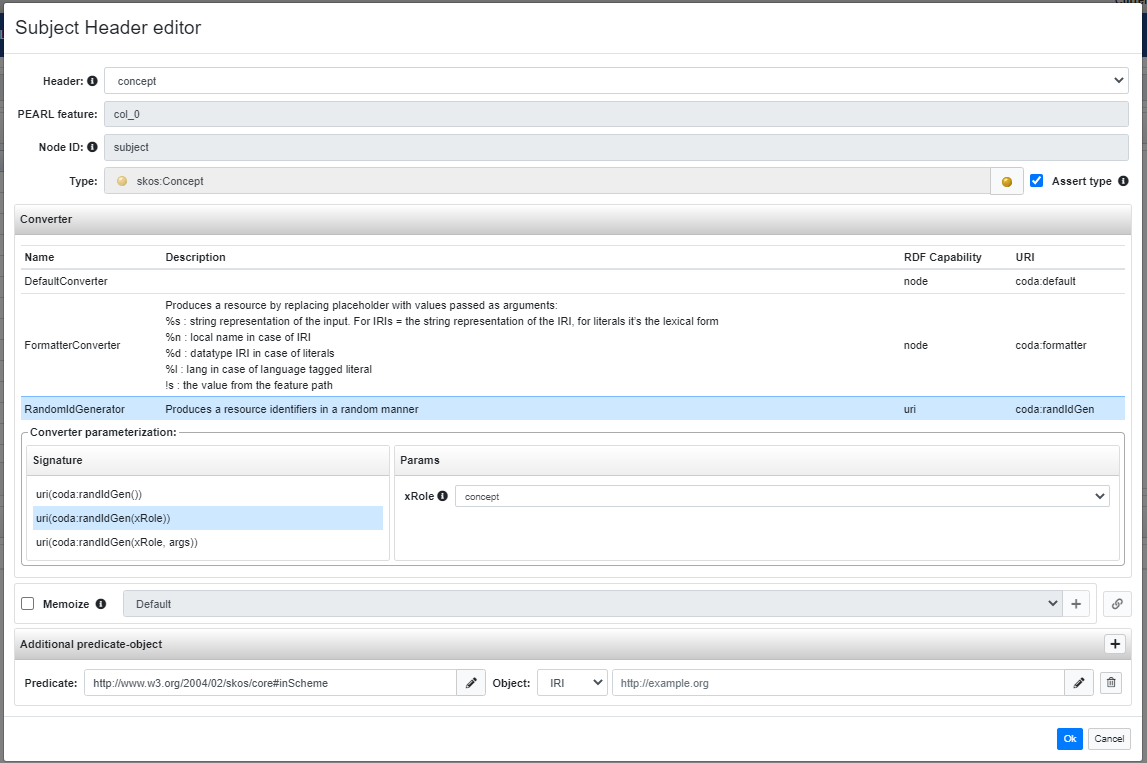
These are the fields foreseen in the form:
- Header: allows to choose, through a combobox, the column that seeds the generation of the subject node;
- PEARL feature: this is a read-only field, it shows the id with which is referred the UIMA features in the PEARL code. It depends from the header selected above;
- Node ID: this is a read-only field too, the subject node ID must be
subjectthat is a reserved ID. In fact, in the editor of the spreadsheet headers, the creation of a node with this name is always denied; - Type: optionally it is possible to assert a class membership for the subject;
At the bottom of this form there is a panel for the configuration of the CODA converter that will generate the subject node. Note that in this case the only available converters are those capable to generate an IRI value.
Finally, a further panel allows the definition of additional predicate-object pairs to relate to the subject resource.
Memoization
When defining the node convertions, in case of different cells that shares the same content, user may want to ensure that the conversions of these cells will result in nodes representing the same resource. This might happen, for example, when the content of a column refers to values defined under another column. This is easily granted when a deterministic converter is used for the conversions, but what if the resource needs be generated randomically? (see this example in the tutorial page).
In this case the @Memoized PEARL annotation comes to the aid. This annotation ensures that the convertion result is cached and reused when the converter is invoked again on the same input.
The header editor allows user to enable the memoization when the randomic converter (RandomIdGenerator) is used.
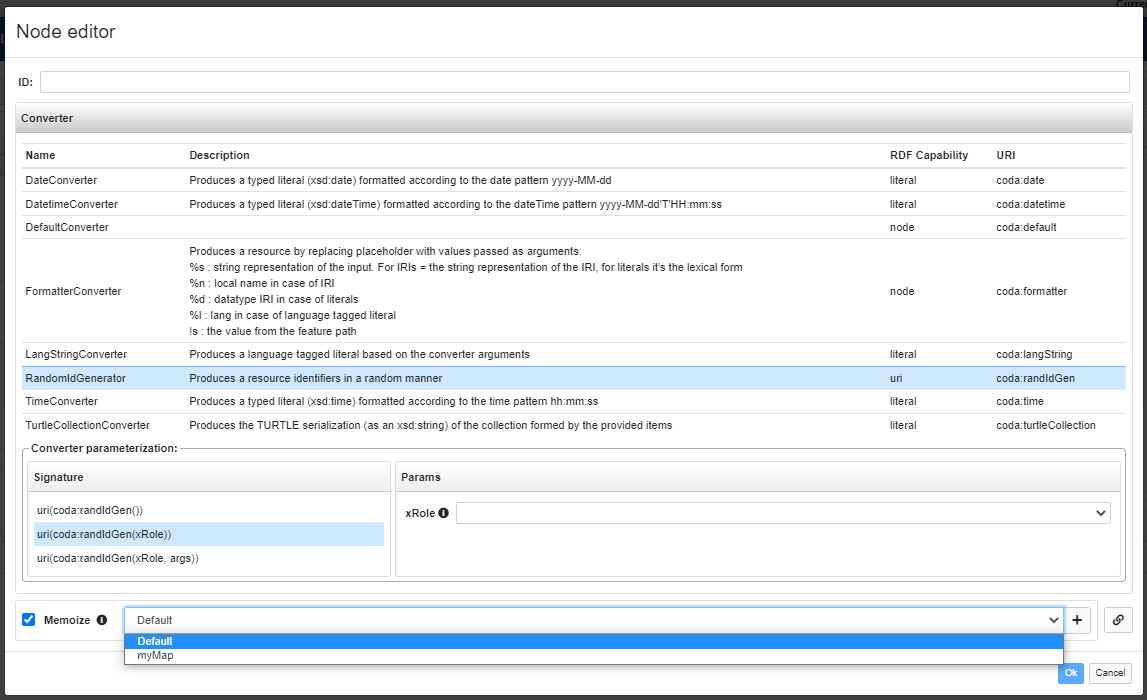
As you can see in the image above, where the randomic converter is chosen for the conversion, a Memoize checkbox is shown at the bottom of the dialog. If activated, it is also possible to select the memoization map where the conversion input-output correspondences will be stored.
Enabling the Memoize option will cause the @Memoized annotation to be applied above the node conversion within the generated PEARL. In case a custom/non-default map is selected, the map ID will be provided as argument of the annotation (e.g. @Memoized(myMap)).
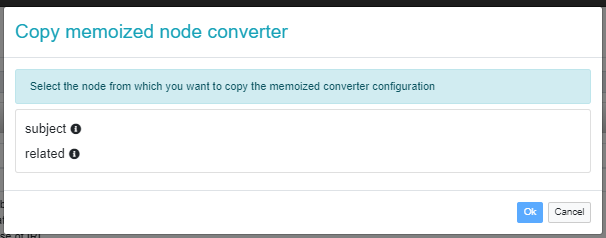
Finally, through the "link" button on the right of the combobox, it is possible to bind the conversion of the current node with one of the existing nodes which conversion exploits the memoization. This is quite useful as it avoids to repeat over and over the same converter configuration for all the nodes the user wants to keep bound. User just needs to click on the button, select the "seed" node and then the converter configuration (signature, parameters, memoization map) is replicated.
The Database Management
To read the data from a Database the user needs to provide the following parameters:
- The Driver to use (it depends on the type of the DB, currently the supported ones are MySQL, MariaDB and PostgreSQL)
- The BaseURL: the url where the DB is (e.g. 127.0.0.1:3306)
- the DB name
- Tables: the list of tables that Sheet2RDF will consider
- User: the username of the account having the rights to access that DB and those tables
- Password: the password of the account having the rights to access that DB and those tables

Once the paramters for the DB have been inserted and the connection has been established, the following steps are exactly the same as those regaring the spreadsheet management
The PEARL editor
Sheet2RDF triplifies the data by following the transformations indicated in the PEARL document. A basic PEARL document can be generated automatically by the system through the generate pearl button ('play' icon in the Spreadsheet preview panel). In most of the cases, if all the headers have been configured, it should not be necessary to edit the code, otherwise it may be necessary to eventually replace placeholders (%pls_provide_...%, that is, part of the PEARL which necessarily need to be filled by the user) with a ground value, or just for customizing the transformation differently from the default choices suggested by the system.
A PEARL document can be loaded from the filesystem or exported in order to reuse it later (2).
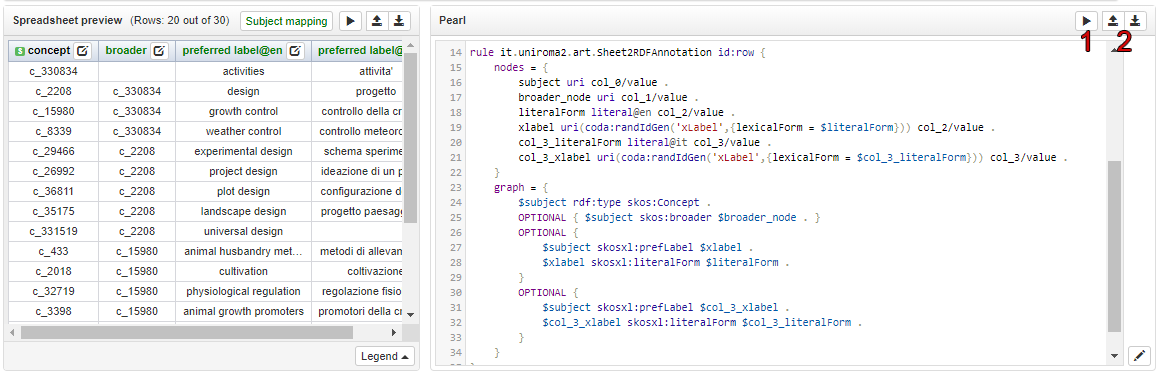
A side note: in the graph section, every patterns, whether deriving from simple or advanced graph application, excluding those reguarding the subject, are written in an OPTIONAL block. This is necessary in order to avoid the failure of the entire graph projection in case a feature is empty (a feature contains the value of the cell under the related column, so a feature is empty if the referenced cell is empty)
When the PEARL code is valid and completed, it can be executed simply by clicking on the "play" button (1). In case of errors in the code, a warning icon (with details shown in a tooltip) appears to the left of this button.
If there are multiple Sheets/Tables, it is possible to generate all the PEARL codes for the various Sheets/Tables. To do so, just use the button in the Multi sheet actions istead of the one from the Spreadsheet preview

Triples generation
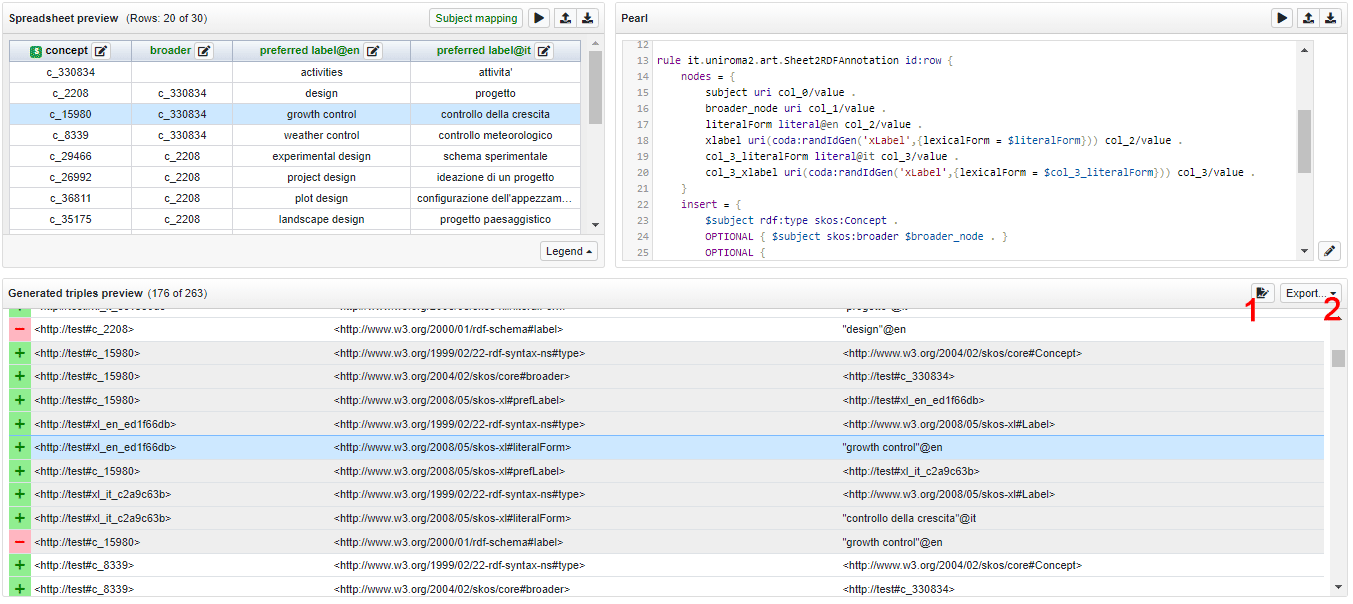
The bottom panel shows the RDF triples that the system generates. In this panel, the triples will be shown with an alternation of background color. The triples with the same color are generated from the same row of the datasheet. Clicking on a specific row of the triples panel, the source datasheet row will be highlighted as in the figure below. Moreover, on the left of each triple, a green plus and a red minus inform if the triples are going to be respectively added or removed
Finally, after clicking on the add button (1), the changes will be applied to the project, namely the triples in addition will be added to the data, those in removal will be deleted.
The triples to add can be also exported in different RDF formats (2).
If there are multiple Sheets/Tables, it is possible to generate all the RDF triples for the various Sheets/Tables. To do so, just use the button in the Multi sheet actions istead of the one from the PEARL