

Architecture
CODA (see figure below) extends UIMA with specific capabilities for populating RDF datasets and evolving ontology vocabularies with information mined from unstructured (or semistructured) content.
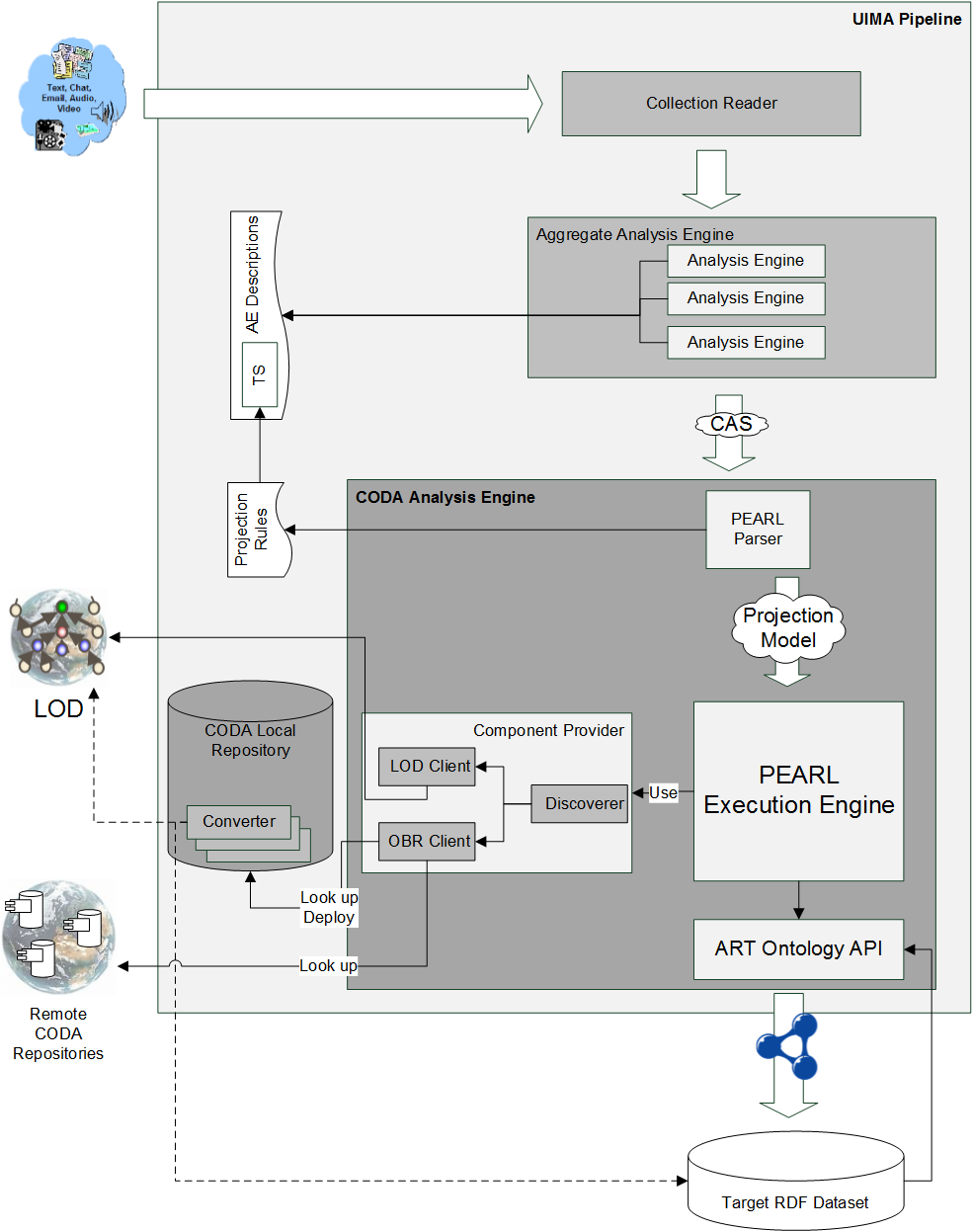
A primary contribution over the standard UIMA pipeline is the introduction of a concrete Analysis Engine (CODA Analysis Engine) targeting the evolution of RDF datasets (Target RDF Dataset in figure), intended indistinctly as knowledge bases or ontology vocabularies. The Analysis Engine delegates domain specific tasks to external components which can be automatically discovered on the Web and deployed into a local repository (CODA Local Repository).
The typical input of CODA is thus an UIMA Analysis chain, together with its associated CAS (for storing UIMA annotations) and the UIMA Type System used to model the data in the CAS. The input is then completed by a PEARL document (more later) detailing how the UIMA metadata is converted into RDF triples.
Exploding the UIMA Analysis Engine
The main task of CODA is to project UIMA metadata contained in a CAS into user defined RDF graph patterns based on a vocabulary of choice. The projection of UIMA metadata into RDF triples is a complex process including the following activities:
- Select relevant content from within the UIMA CAS;
- Turn entities in this content into RDF nodes;
- Build an RDF graph from a user defined graph pattern, binding the produced RDF nodes through triples.
In order to support the user in the specification of this process, CODA provides a rule-based pattern matching and transformation language, called PEARL. (ProjEction of Annotations Rule Language)
The PEARL Execution Engine is the component implementing the PEARL operational semantics. This engine orchestrates the triplification process, executing PEARL rules against the CASes produced by the UIMA workflow and generating triples out of it.
PEARL is also an extensible language, in that the functions used to convert the UIMA feature structures into RDF Nodes are implemented through dedicated components, called converters. The CODA framework implementing the above architecture comes bundled with a few standard converters, however, new converters can be easily developed, in the form of OSGi bundles implementing the converter interface. Converters, when phisically available, can be dropped inside the <...> folder of the system. A resolution mechanism (described in the next section) is also available for discovering converters on the web and for downloading and installing them automatically.
Conversion Mechanism
PEARL syntax covers UIMA metadata selection and RDF graph construction patterns. Conversely, the construction of RDF nodes out of UIMA metadata is an overly variegated task, possibly depending on domain/application specific procedures for composing URIs/literals, or possibly on external services for identity resolution (such as OKKAM). In order to preserve its simplicity, the PEARL syntax provides specific extension points for delegating this task to external components, called converters.
Converters are indirectly referred by means of a URI which identifies the desired behavior (a contract) instead of a concrete implementation. In a certain sense a contract identifies a set of functionally equivalent converters, possibly differing for non functional properties, such as resource consumption, performance with respect to the task, or even licensing terms. Borrowed from the distinction between abstract and concrete services in the Service Oriented Architecture (SOA), the distinction between contracts and converters helps the reuse of projection specifications, since an application can bind the contracts to the converters best fitting its own requirements.
Autonomous Configuration and Extensions Deployment
The PEARL execution logic is kept separate from the contract resolution process as contract references are resolved by the Component Provider (see figure, connected to the PEARL Execution Engine) into suitable converters. Converters are bundled conforming to the OSGi specification and stored in repositories organized according to the OBR (OSGi Bundle Repository) architecture. OBR repositories maintain metadata about the hosted bundles including their name, version, provided capabilities and requirements. Descriptions of CODA converters complete the metadata with information about the implemented contract and their non functional properties.
Converters are physically retrieved from OBR repositories through the OBR Client module. Their resolution follows a two-step procedure: when a converter for a given contract is needed, the OBR Client accesses a known set of OBR repositories (starting from the CODA Local Repository) looking for a candidate whose metadata match the contract. If no candidate is found, the Component Provider relies on its Discoverer module to explore the Web looking for additional repositories. The Discoverer exploits the fact that PEARL specifications are self-describing and, moreover, grounded in the Web, since the required contracts are mentioned through dereferenceable URIs. In compliance with the Linked Data principles, the Discoverer obtains through those URIs an RDF description of the contract, including a list of authoritative repositories of known implementations.
This architecture enables autonomous configuration of CODA systems, disburdening the user from manual settings prior to the execution of a PEARL projection. This is especially valuable when reusing PEARL documents written by third parties and relying on converters available on the web, thus in an open and distributed scenario.
Access to the RDF Dataset
The execution of a PEARL specification on a given CAS produces a set of triples which are eventually committed to an RDF triple store. The interaction with a triple store is mediated by the OWL ART API, an open RDF middleware providing implementations for different triple store technologies.
Deployment and Use
Two different application scenarios are possible:
- CODA can be integrated inside a general UIMA pipeline, by means of a dedicated implementation of the UIMA Analysis Engine interface (as shown in the figure above);
- a CODA based application may get the output of UIMA and process it
Also, the system has two deployable solutions:
- as a stand-alone solution: CODA is a jar library file, and you may load extensions and components by specifically adding them to the classpath (or, for some of them, by discovering them on the web)
- Use it as an OSGi bundle inside an OSGi container. In this case, component resolution is seamlessy ranging from the locally loaded OSGi bundles to components discovered on the web. This solution is compatible only with the CODA-based application scenario.