|
|
|
|
Site Index:
In This Section:
|
ARTInternal Research Project
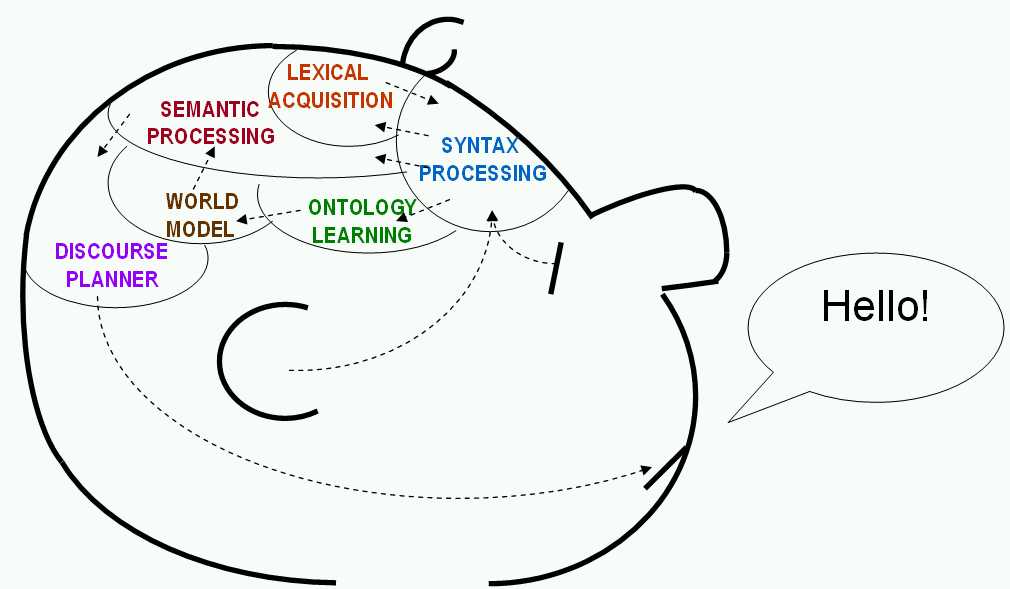
Language-driven Ontology learning for Question Answering It is nowadays, widely accepted that linguistic information is relevant in ontology engineering at least for two main reasons. First, ontologies are data models whose concepts are identified by names and processing such information under a linguistic perspective is helpful in the understanding of the often implicit semantics imposed by the knowledge engineer. Harmonisation of domain ontologies throughout the use of linguistic resources has been for example proposed in (Magnini et al., 2002). Second, although ontologies capture aspects of the semantics that are somewhat independent from linguistic information, most text processing applications (e.g. knowledge-based IR or question answering) require explicit mapping between domain concepts and their textual counterparts: an example is given by the terminology (e.g. multiword expressions) that embody linguistic variants of an often complex concept in the ontology. Other examples are event matching rules in information extraction systems. Although targeted to specific event types, IE systems must be aware of the different ways the events are linguistically expressed: which verbs and which concepts are used to communicate a given event? This form of lexical semantic information is strictly part of the ontological description especially with respect to paradigmatic properties. An event type e is a specific concept and when inheritance is required it may be connected with topological properties in a hierarchy. However, these semantic dimensions are independent from the linguistic properties (e.g. the rules needed for detecting potential realisations of e in textual material). Linguistic rules should include a combination of syntagmatic S and semantic M constraints that a text t must satisfy in order to realise e. In other words when S(t) Ù M (t) is a true formula then we can state that t realises e, i.e. "t.S(t) Ù M (t) Þ e(t) Rules like the above one are needed for IE over data sets of a realistic size, although they are usually not represented ontologically. Examples of properties S or M are for example distributional properties (e.g. mutual information of word collocations in corpora) able to suggest a concept (e.g. a terminology item that represents a concept in the domain) or a relation. Machine learning techniques are widely used to observe these properties and inductively develop the required concepts/relations. However, once learned they are usually mapped into the target KB throughout validation (often manual, as in (Bozsak et al., 2002)) that determine the (new) topological properties and their implicatures. As a consequence the textual semantics of a concept or a relation is not preserved in the target ontology. Syntagmatic and semantic properties are used to justify the eligibility of a given lexical ( structure) as an ontological concept but are then neglected. The textual properties that were used to justify an inductive decision (e.g. a given fragment is a terminological expression, a given syntagmatic structure is a prototypical rule for the relation or event type e), are not associated (after the decision is taken) to the resulting concept or relation type. Although such properties in principle depend on the underlying domain ontology, they are never explicitly represented. Rare exceptions are works where integration between world and textual semantics for text understanding is adopted as in (Hahn and Schnattinger, 1998; Hahn and Mark, 2002). In ART (intelligent Agent at Roma Tor vergata), we define a framework where specific lexical semantic information can be integrated as an inherent component of an ontology. The advantage here is that the enriched information is made available even in the early phases of the ontology engineering process. Ontology learning is thus mapped into an incremental process here should be thus adopted where NL learning interleaves with ontology engineering. In the proposed framework we at least need to make available the following semantic components:
ART will be based on such a representational framework and its implementation will be based on Semantic Web standards as SOAP, WSDL and OWL. ART will be able to learn extensively from corpora its target ontology with weakly supervision from the knowledge engineer. Then, ART will be able to sustain dialogue and question answering about the target domain by exploiting in combination NLP and ontological reasoning. Involved People
Specific Publications
Start Date: September 2004
|
|
Thanks Department to: |
Roberto Basili's Home, 2005 |