|
|
|
|
Site Index:
In This Section:
|
SensumInternal Research Project
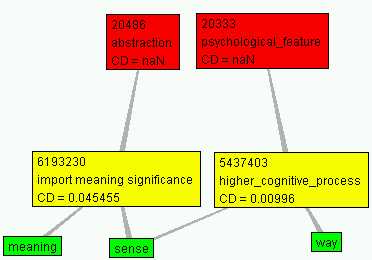
In general, semantic disambiguation is motivated by the fact that current language processing models are considerably affected by sparseness of training data, and current solutions, like class-based approaches, do not elicit appropriate information: the semantic nature and linguistic expressiveness of automatically derived word classes is unclear. Many of these limitations originate from the fact that fine-grained automatic sense disambiguation is not applicable on a large scale. In Sensum, a weakly supervised method for sense modeling (i.e. reduction of possible word senses in corpora according to their genre) and its application to a huge corpus, aiming to coarsely sense-disambiguate it, is studied. This can be viewed as an incremental step towards fine-grained sense disambiguation. The underlying sense catalogue adopted in the experiments is Wordnet. The created semantic repository as well as the developed techniques will be made available as resources for future work on language modeling, semantic acquisition for text extraction, question answering, summarization, and many other natural language processing tasks. Involved People
Sensum
Internal page >>> Specific Publications
Start Date: September 2003
|
|
Thanks Department to |
Roberto Basili's Home, 2005 |